Multimodal AI you can deploy anywhere
Next-generation AI models to empower agents that can see, hear, and speak.
Try it out yourself.
Would you rather use our API? We’ve got you covered!
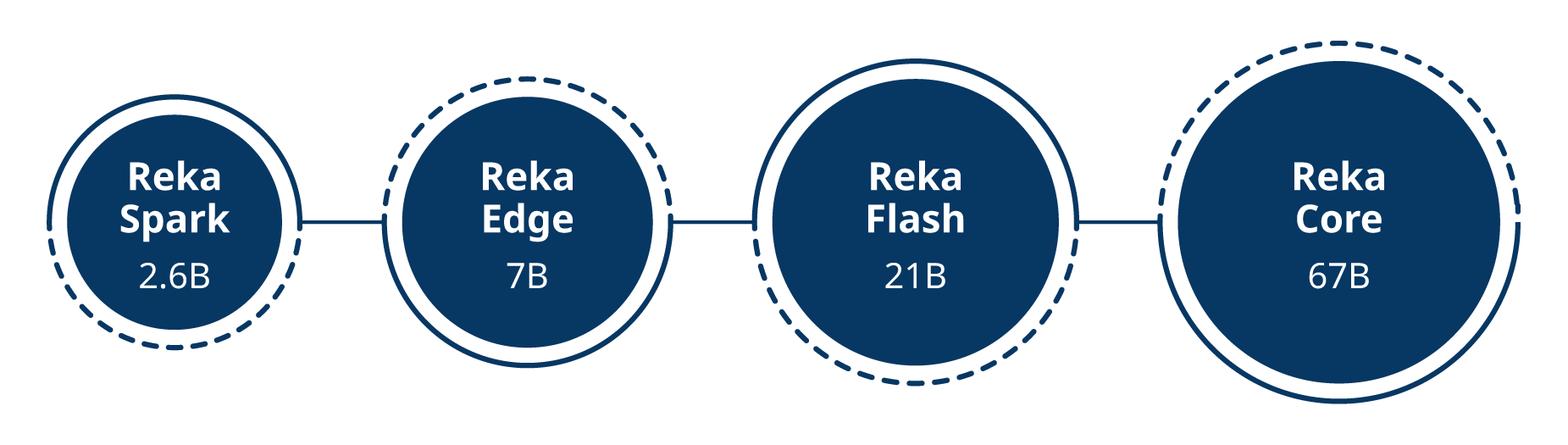
Our World-class Models - Core, Flash, Edge & Spark
Our models are efficiently trained from scratch across a vast fleet of thousands of GPUs. Each model in our lineup is natively multimodal, meticulously designed to meet a distinct set of requirements. Reka Core, our flagship model, rivals industry leaders such as OpenAI, Anthropic, and Google, demonstrating competitive performance across widely accepted evaluation metrics. On the other end of the spectrum, Edge and Spark are compact models optimized for on-device execution, while Flash, our Turbo-class offering, is pushed to its absolute limits to provide significant performance at fast speeds.
Read our Technical report on Reka Core
Natively Multimodal
Reka’s multimodal models can perform many tasks such as generating textual descriptions and structured taxonomies from videos and images, translating speech and audio from and to many languages, and answering complex questions from long multimodal documents, writing and executing code, and many more.
Describe the setting, action, and character in this video
The video is set in a location that has a house with a pool overlooking the sea. The video shows someone jumping into an infinity pool from the edge of the house. They then swim in the pool. Regarding the person, they appear to be a woman. She is wearing a black swimsuit.

Where was this taken?
This image was taken in San Sebastián, also known as Donostia, a coastal city in the Basque Country, Spain. The perspective is from the promenade along the Bay of La Concha, looking towards the city center. The bay is one of the most iconic features of San Sebastián, and the cityscape with its historic buildings is a well-known view of the area. The presence of the sea wall and the style of the buildings, along with the mountainous backdrop, are characteristic of this region.
What is happening here?
The video shows a person using a table saw to cut a piece of wood. The person is wearing blue gloves and is using a push stick to guide the wood through the saw. The saw blade is visible and the wood is being held in place by clamps. The person adjusts the clamps and the wood before starting the saw.
Model capabilities
Each of our models can be fine-tuned and customized, including using your own proprietary data, securely for deployment in the cloud, on-premises, or on-device.
-
Image and video comprehension
Achieve a deeper understanding of your multimodal data and solve problems beyond text with our natively multimodal models
-
General reasoning
Understand and apply everyday knowledge to solve problems and tasks that require logical deduction and inference, making it suitable for complex problem solving
-
Multilingual understanding
End to end support for 32 languages in both text and spoken form
-
Tool use, function calling, and coding
Execute tasks, unlock agentic flows and automate AI driven solutions with our models’ function calling capabilities.
-
Speech input and output
Bring new products to live with the ability to comprehend and respond speech.
Advanced writing and reasoning capabilities
Our models have advanced reasoning capabilities to solve a wide range of complex problems.
-
Imagine a plot for a crossover between Dune and Dora the Explorer
Dora and Boots stumble upon a mystical portal leading to Arrakis, where they join forces with Paul Atreides and the Fremen to find the hidden spice mines and thwart the Harkonnens' plan to dominate the universe, all while teaching valuable lessons in teamwork and problem-solving.
-
How can you stack a bowl, egg, ball and book in a stable way?
Begin with a flat book as the base. Place an upside-down bowl on the book, securing its edges. Nestle an egg inside the bowl against its curve to prevent rolling. Finally, center a ball on top of the bowl, distributing its weight evenly. This stack leverages each item's shape for stability.
-
What is the least number of coins required to make a total of USD 1.35?
The least number of coins required to make $1.35 USD using standard U.S. coin denominations (penny, nickel, dime, quarter) is 6 coins: 5 quarters and 1 dime.
Deployment Methods
With flexible deployment options centered around your privacy and cost-efficiency
-

API
All models are available via our API. Get started today and build the AI features you need with our models.
-

On-premise
Deploy our model weights on your own infrastructure. Maintain your data and privacy requirements.
-

On-device
Add low latency cutting edge multimodal intelligence to your devices with locally served model.
Explore Our Models
-
Try Now
Explore all our models on Reka chat. Try our image and video comprehension or solve complex problems.

-
Use our API
Start integrating our models into your products today with our API. No complex pricing plans, just pay for what you use.
Our Partners






Latest News & Articles












Join Our Team
Join us in this exciting journey and experience a new era of growth.